用“主方法”秒算分治算法时间复杂度
课堂导入与主方法初窥
 在cs101 spring的第二节课:归纳式与递推式 上,我们了解到了将任务分解与组合来完成,从而降低任务的时间复杂度的概念。但是,要怎么判断一个任务是否适合通过分治(divide & conquer)来进行解决呢?很多人第一反应是画递归树。但当结构变复杂时,画树不仅费时还容易算错。在课件的最后,老师引入了解决这个问题的方法,也就是我们今天的话题:主方法(Master Theorem)
在cs101 spring的第二节课:归纳式与递推式 上,我们了解到了将任务分解与组合来完成,从而降低任务的时间复杂度的概念。但是,要怎么判断一个任务是否适合通过分治(divide & conquer)来进行解决呢?很多人第一反应是画递归树。但当结构变复杂时,画树不仅费时还容易算错。在课件的最后,老师引入了解决这个问题的方法,也就是我们今天的话题:主方法(Master Theorem)
核心公式与“三巨头”(主方法的定义)
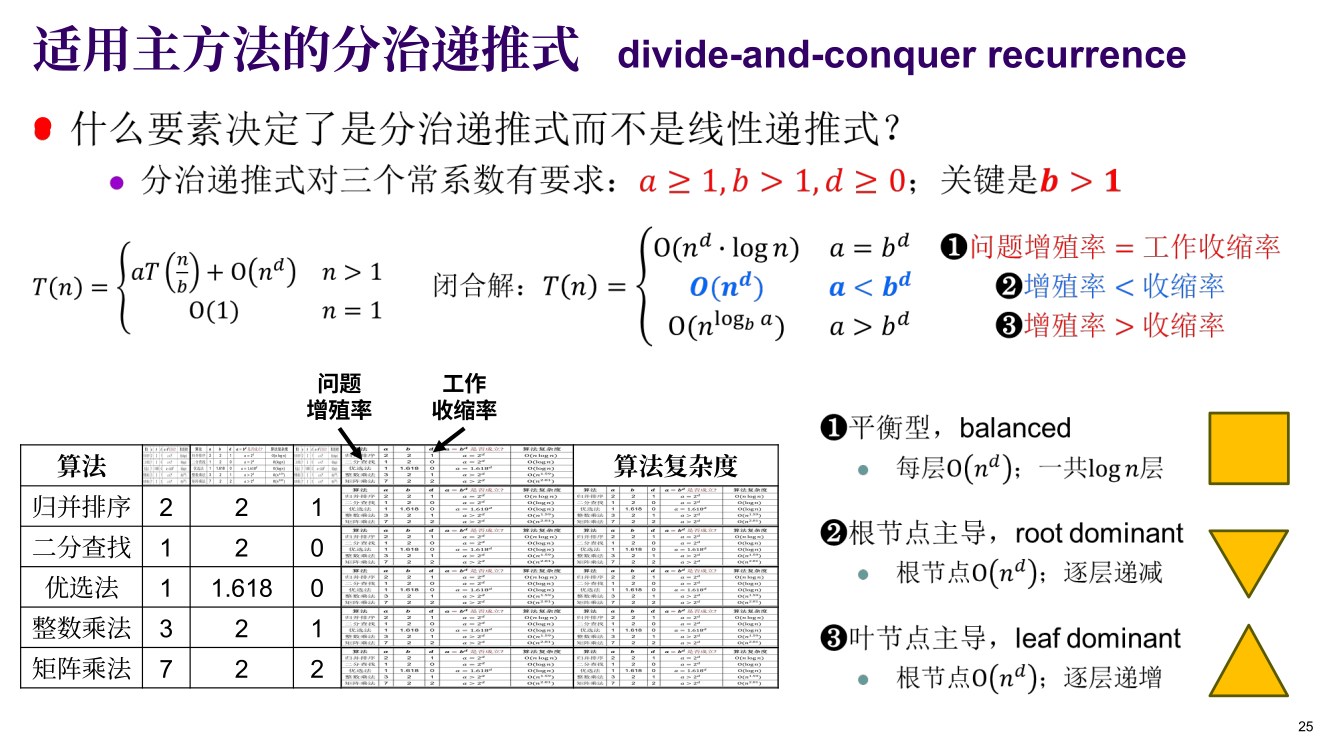
分治算法的时间复杂度通常可以抽象为以下标准形式的递推公式:
$$T(n) = aT(n/b) + O(n^d)$$
要用主方法,必须满足一个大前提:$a \ge 1$ 且 $b > 1$。公式里的变量分别代表算法的物理执行过程:
- $n$:问题的总规模。
- $a$:每次递归,将问题分解成的子问题数量(分成了几个)。
- $b$:每次递归,子问题规模缩小的倍数(例如 $b=2$ 就是对半砍)。
- $O(n^d)$:分解问题和合并结果所消耗的时间开销。

底层逻辑:一场“根”与“叶”的较量
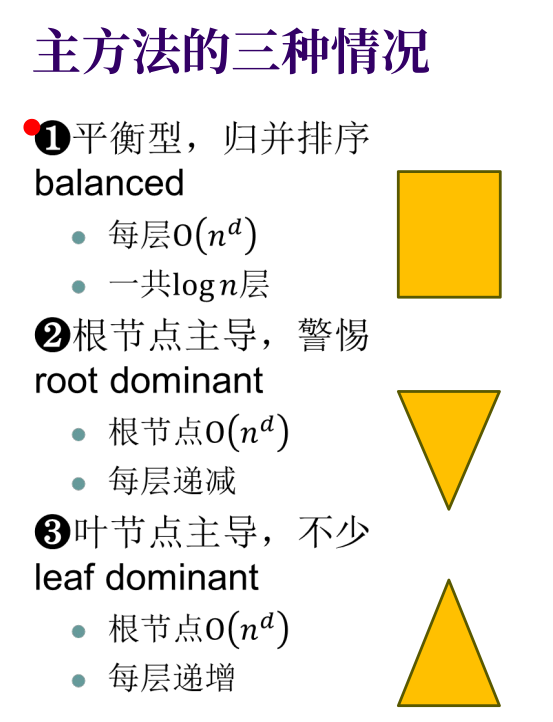
主方法的本质,是比较**“分解/合并的成本(根节点主导)”和“解决所有微小问题的成本(叶节点主导)”**哪一个更大。
这里引入一个关键的“分水岭多项式”(Watershed Polynomial):$n^{\log_b a}$,它代表了叶节点的总个数。我们将合并成本 $O(n^d)$ 与分水岭多项式进行比较(或者直接比较 $a$ 和 $b^d$),会得出三种情况:
情况 1:叶节点主导(子问题太多啦!)
- [cite_start]条件:$a > b^d$ (问题增殖率 > 工作收缩率)。即余项远小于分水岭多项式,递归成本远大于合并成本 [cite: 16]。
- 结论:时间复杂度由叶节点数量决定,为 $O(n^{\log_b a})$。
- 例子:分治法求最大值
- 切成两半($b=2$),两边都要找($a=2$),最后只需做一次比较运算($d=0$)。
- $2 > 2^0$,复杂度为 $O(n^{\log_2 2}) = O(n)$。
情况 2:势均力敌(各层开销均衡)
- [cite_start]条件:$a = b^d$。递归成本与合并成本在一个数量级 [cite: 15]。
- 结论:每一层的开销乘以层数,复杂度为 $O(n^d \log n)$。
- 例子:归并排序 (Merge Sort)
- 对半折分($b=2$),排两个子数组($a=2$),合并时需要双指针线性扫描($d=1$)。
- $2 = 2^1$,复杂度为 $O(n \log n)$。
情况 3:根节点主导(合并太费劲了!)
- [cite_start]条件:$a < b^d$。合并成本远大于递归成本,分治反而增加了复杂度 [cite: 16]。
- 结论:时间复杂度由根节点的合并操作决定,退化为 $O(n^d)$。
- 例子:暴力计算分界逆序对
- 切两半($b=2$),算两边($a=2$),但合并时为了找跨界逆序对,使用了双重嵌套循环寻找($d=2$)。
- $2 < 2^2$,复杂度直接退化为 $O(n^2)$。
⚠️ 避坑指南与拓展
Q:$a$ 和 $b$ 必须一样吗? 当然不是。最经典的例子就是二分查找(Binary Search)。虽然数组在逻辑上被分成了两半($b=2$),但我们只去其中一半查找,所以真正执行的子问题数量 $a=1$。此时 $d=0$,$1 = 2^0$,属于情况 2,复杂度为 $O(\log n)$。
Q:$b$ 必须是整数吗? 也不是!看看“反面教材”臭皮匠排序(Stooge Sort):它每次排序前 $\frac{2}{3}$,再排后 $\frac{2}{3}$,再排前 $\frac{2}{3}$。一共递归 3 次($a=3$),每次规模缩小到原来的 $\frac{2}{3}$,所以 $b=1.5$。 结果极其糟糕:$O(n^{\log_{1.5} 3}) \approx O(n^{2.71})$,比冒泡排序还要慢!这也直观地说明了,如果问题缩小的幅度不够大($b$ 太小),会导致算法性能极其堪忧。